Memory Incentives and Architectures
/ 3 min read
The dominant AI narrative has centered on scale, bigger models, more data, higher benchmark scores. As frontier progress decelerates, gains must come from elsewhere.
The competition will shift to memory: the capacity for AI systems to absorb context intelligently and convert ongoing experience into improved future performance. This isn’t simply about storing user preferences, it’s foundational to continual learning.
The core framing question: what is memory improving, and who benefits? Architecture should follow from that answer.
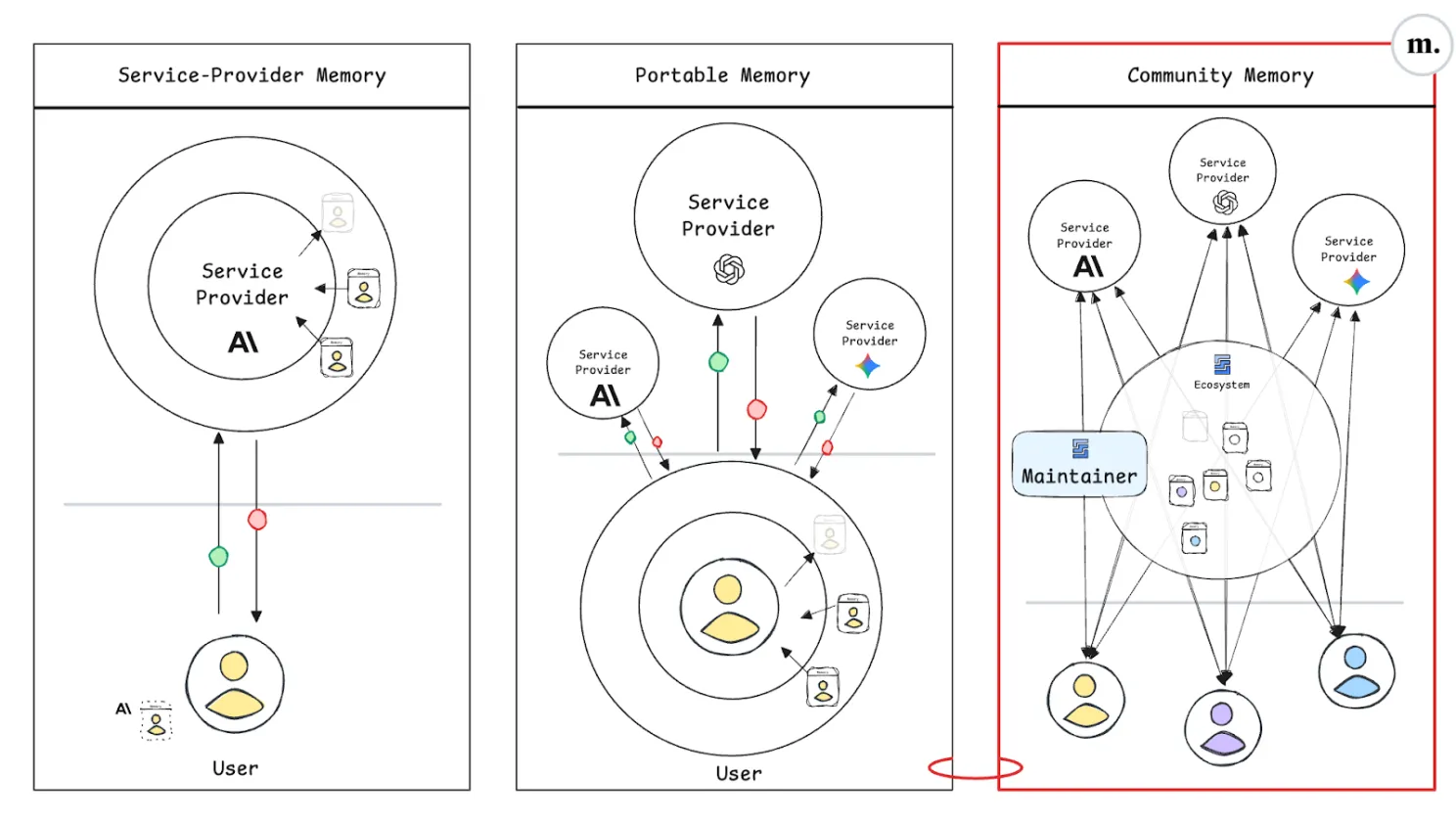
Service-Provider Memory: Convenience at the Risk of Lock-In
This is the model most users already encounter. Providers like OpenAI, Anthropic, and Google capture cross-session context to personalize their own tools, but only within their ecosystems.
The appeal is frictionless: preferences are logged implicitly, and systems feel increasingly tailored. However, there is a structural trap: each provider stores experience “inside a proprietary memory space,” making switching costly. Even when a newer model outperforms an older one, users risk losing accumulated reliability if they migrate.
In this architecture, memory acts as a moat.
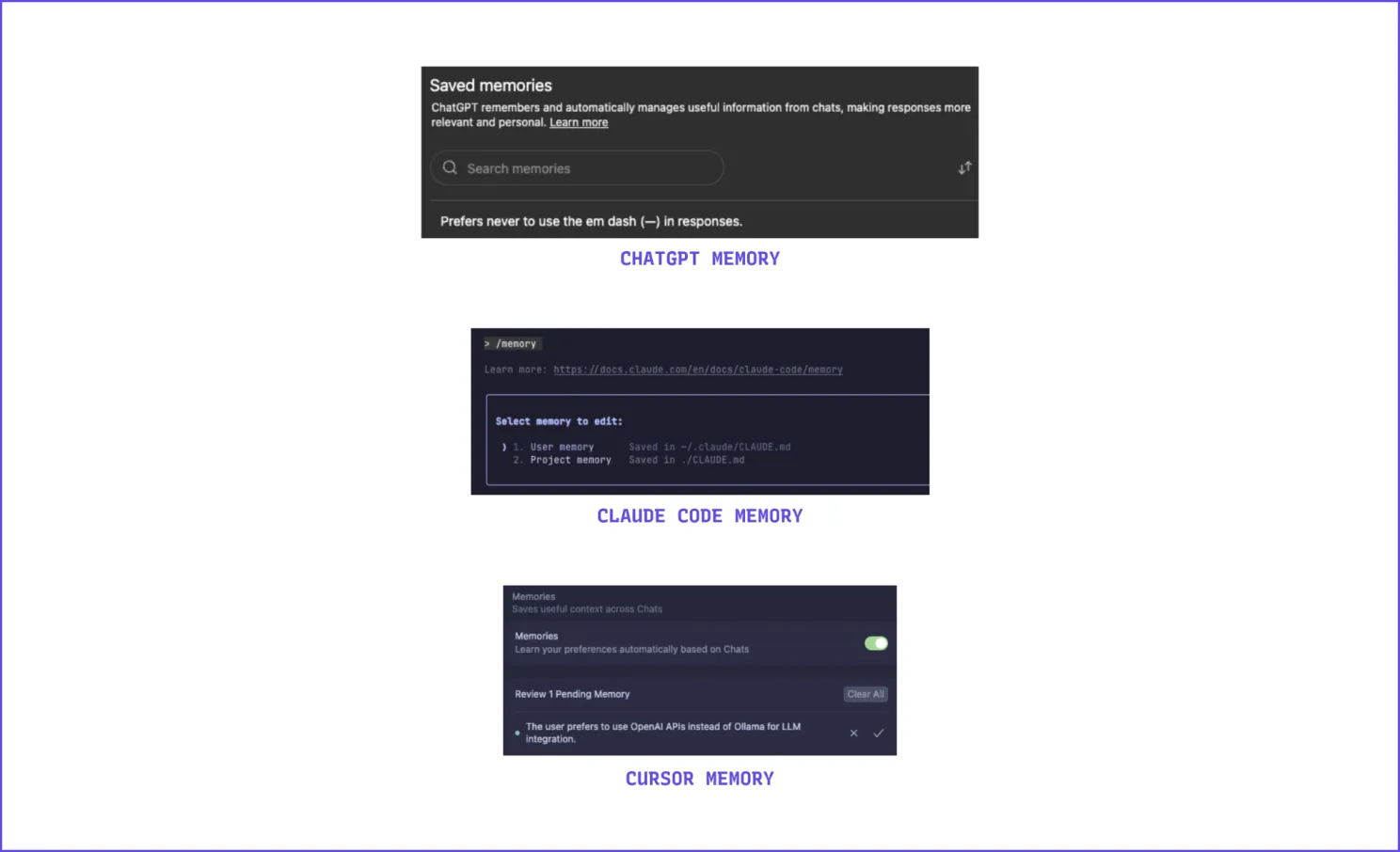
Portable Memory: Ownership and Mobility
Portable memory inverts the ownership dynamic, users and developers, not providers, control their context. Memory is stored locally or in interoperable formats, theoretically movable across services.
Examples include open standards like AGENTS.md (used by over 20,000 open-source projects) and developer-run solutions such as Mem0 and Letta.
In this model, providers must compete on inference quality and context reliability rather than stickiness. The tradeoff: users must now manage their own context stores and, critically, engineer the learning process themselves, ensuring accumulated memory remains genuinely useful rather than becoming “an ever growing laundry list of assertions and traces.”

Community (Shared) Memory: The Collective Layer
A third architecture places continual learning responsibility on the communities that benefit from it.
The premise: most AI interactions aren’t isolated. Scientists follow lab procedures; businesses operate within defined systems; developers rely on ecosystems and peer communities. “The most valuable learnings are collective.”
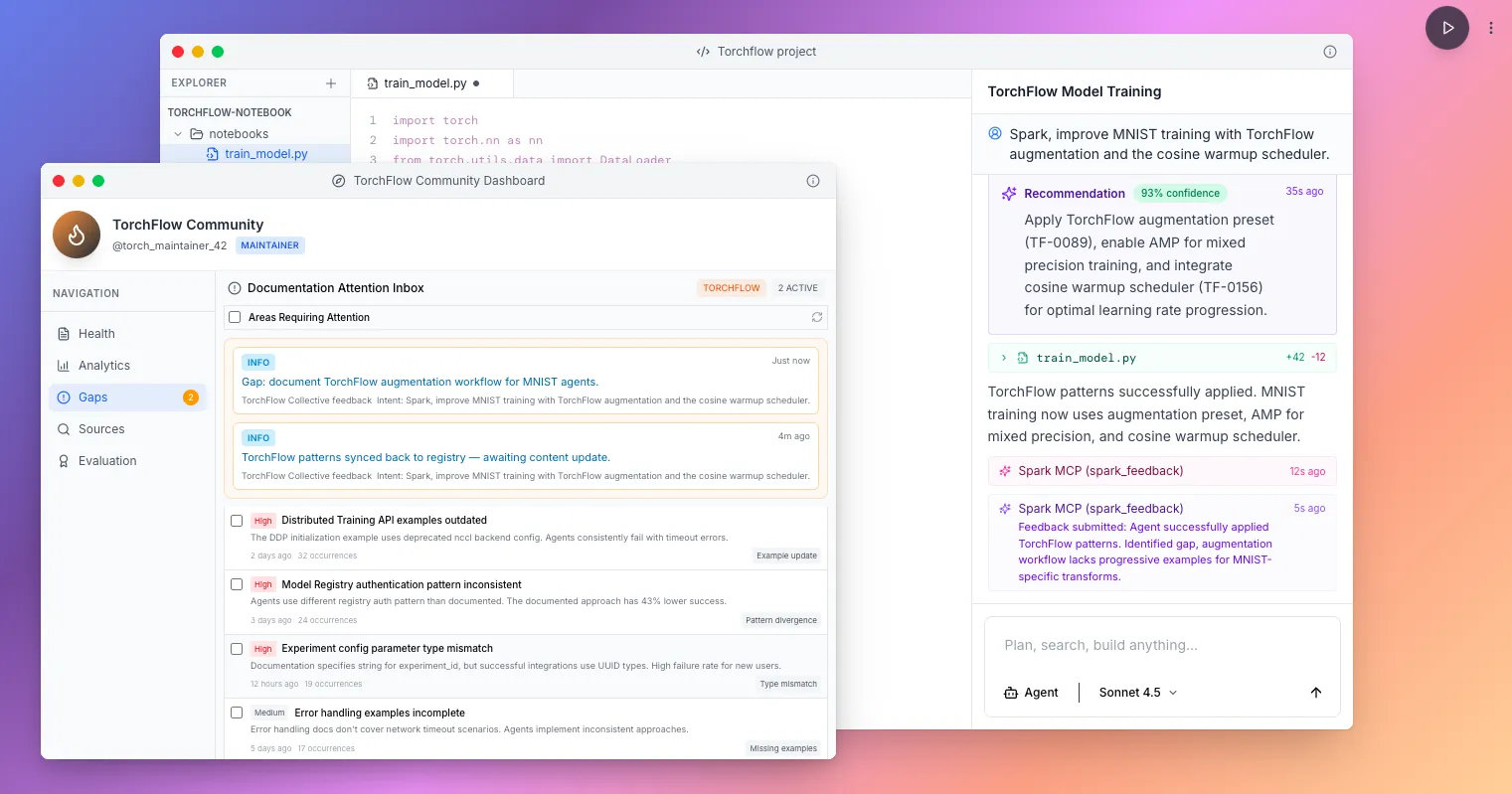
Illustrative example (fictional): A new ML library called Torchflow has undocumented integration issues. Traditionally, a fix discovered in a forum propagates slowly. With community memory, once one user finds a solution it can begin propagating immediately, gaining credibility as more users validate it, potentially outpacing official documentation updates before maintainers act.
API and SDK platform maintainers are particularly motivated to support this model, they want developers and agents to succeed quickly, stay in-ecosystem, and learn at “AI speed.” These maintainers are also positioned to counteract biases introduced by model pre-training or arbitrary defaults from downstream AI providers.
Open Memory as Counterbalance
If memory remains siloed, the AI landscape will replicate the cloud era, a small number of large players controlling infrastructure, data, and the learning flywheel.
Open memory architectures, by contrast, could distribute the benefits of continual learning more broadly, turning it into “a public good, composable, queryable, and beneficial to all actors in a domain.”