Evaluating LLM Apps - The Works on my Machine Problem
/ 12 min read
Read the full article on Moonsong Labs
Introduction
In our previous blog post, we introduced Unravel.wtf, a prototype designed to test whether machine learning can enhance the human readability of Ethereum transactions beyond what algorithmic labeling offers today. As we embarked on building Unravel, one of the core issues we wrestled with was how to design an inference pipeline and measure the quality of its results.
In this installment of our series, we’ll delve into our notes and learnings in evaluating LLM (Large Language Models) applications. Evaluations (often shortened to “Eval”) refers to the practice of measuring empirically the ability of generative models or language model programs to produce the desired results or result distribution (imagine a range of possible answers that are considered “good”).
In this article, we’ll share our observations on the shift in mindset needed to explore the unique challenges posed by testing generative AI applications, and discuss potential approaches and tools to navigate these hurdles. Whether you’re a developer wrestling with LLM evaluation or simply curious about the intersection of AI and Web3, this post aims to shed light on some of the challenges in taking LLM-based applications to production.
The New “Works on My Machine” Problem of LLM Applications
A core challenge in applying AI to existing or new production-grade applications is the shift from impressive, single-use demos to production-quality systems that can scale reliably. While initial prototypes (like ours) can showcase the potential of an application in small samples, scaling these systems to handle diverse real-world scenarios is a different challenge altogether. The possible inputs and outputs increase, and so does the bar on what is considered good enough results. Although we didn’t take Unravel beyond the prototype stage, we deliberately tested the boundaries of it to learn more about the challenges involved.
We often found ourselves asking: “Is it working, or is it just working with the handful of examples we are testing with?” This modern twist on the classic “works on my machine” problem uncovers two important topics when relying on statistical outputs from an LLM versus deterministic instructions1.
Challenges of Defining Quality
Not all outputs have an easy-to-test definition of quality, so you need to choose a technique to define and test for quality for your specific context. Even slight errors can quickly affect users’ perception of quality, as users instinctively judge the underlying system from just a few interactions. Building and maintaining trust with users is harder when relying on statistical outputs—even a well-known brand can lose trust overnight. Remember Bard?2
Let’s take Unravel as an example, the aim is to create a human readable transaction that clearly articulates the transaction intent(s).
What constitutes a good quality result for intent unraveling? We could argue that it needs to be:
- Factually correct: this means, first order information – like numbers, dApps names – are correct, and second order information (information inferred through our app like actions, purposes) should be also measurably accurate predictions
- Helpful and intuitive: this means a transaction summary – for example – should choose the right words, structure and steps to convey a simple and intuitive summary to a non-expert. Let’s take a (wrong) example of a transaction intent: 0xca5237…ffbe88
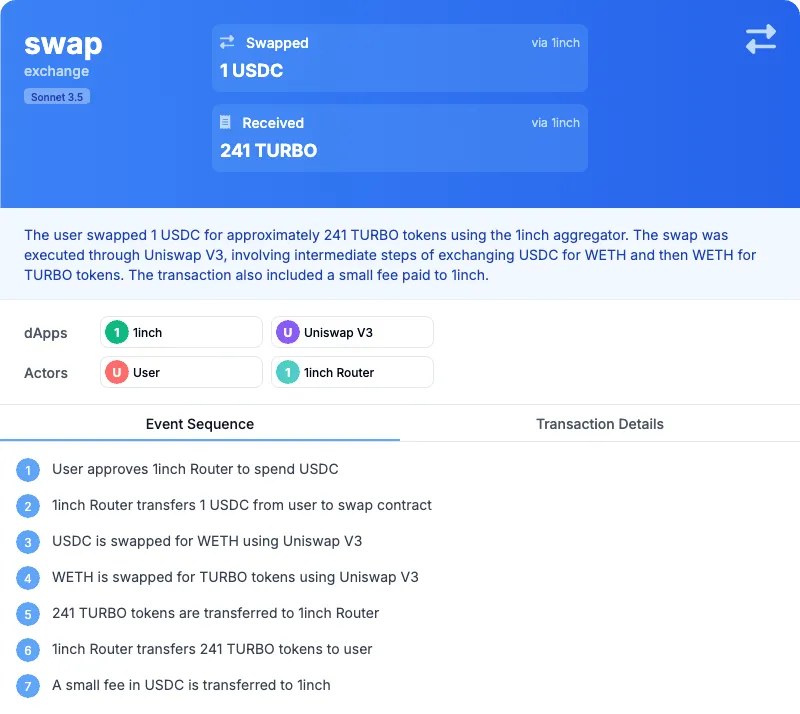
1/ Is it factually correct?: This shows a first order mistake, the intent shows a swap of 1 USDC when the real value of the USDC transferred is 1000 as verified on Etherscan , this is a decimal “hallucination”. To control for this error, we could introduce and ensure high rank in the context for the number of decimals of the ERC20 contract in question, and run this fix against a sample that previously failed.
LLM are notorious for offering confident yet subtly wrong responses, intent interpretation – as we saw in the previous blog post – falls in the bucket of the task that is relatively expensive (time wise) to verify manually and unstructured fields that don’t have a clear test can be subject to those errors. In those cases, the user’s instinct will be playing an important role in their judgment of your service quality, if they spot something that is off (our current prototype offers plenty of examples for it), it is unlikely they will use this tool again when reaching for information they can rely on.
2/ Helpful/Intuitive: Is the description of the intent helpful and intuitive? How do we define “helpful” and “intuitive”? To measure this, we could use manual reviewers following a qualitative definition of helpfulness, we could define some heuristic to be followed by an LLM ranking responses to scale that evaluation. Alternatively, we could define derivative tests (such as answering 5 specific questions about the transaction within a time limit), if a user is able to retrieve the right information and answer correctly (faster and better than Etherscan), then the intent is helpful and intuitive enough.
Challenges in Engineering for Quality
In complex, agentic systems—particularly those that perform tasks autonomously—tweaking a prompt to improve performance in one area can inadvertently cause regressions in another, in ways that are hard to predict or measure. Introducing elements of reinforcement learning can improve your system in the areas you are measuring and rewarding, yet users can observe regression in other areas you haven’t considered.
In our previous example, if we tweak the way we structure our context or prompt to improve our interpretation of the decimals in ERC20 contracts, other properties of our interpretation might suffer as a result and might go unobserved (particularly things you don’t have an eval for).
A final—perhaps obvious—point that applies to both is that regardless of how you are using LLMs nowadays, either as a service or self-hosted, there is always a meter running. You will either have to improve quality within a $/token budget you have been given or wrestle with the opportunity cost over your own or rented hardware (more testing for this product, or more training days for the next?).
Observations to Engineer for Quality
While there are many interesting libraries and techniques one can use to measure the quality of an LLM application, the truth is that it often starts before you write a single line of code.
Defining the (sub-)task your language model program is meant to accomplish and manually curating a test set overshadows much of the other solutions. You can then scale those further once you have a baseline to start from.
This is quite hard (and often not really fun!) You are perhaps reaching for an LLM precisely because the task or workflow you want to cater to is hard to define in instructions, but unfortunately, if you want to have some control of quality, there is no escaping this step. The size of the sample, depending on the technique you use, can start small (20/30 observations you can manually create) so long as it correlates with the distribution you are likely to observe. As you collect and grade responses, you will collect a bigger sample and define more edge cases you want to add observability and eval for.
Once you have defined the (sub-)task, then you are most likely moving to a form of “parameter search” on your prompt using your test set: What is the best prompt & pattern to use to reliably capture the type of result you are after?
One of the challenges in Unravel was interpreting contracts and calls in the context of a broader transaction, individual actions carry a very different meaning when judged in isolation, yet some transactions might include many calls, making “all at once” unraveling not possible with today’s constraints in context size and accuracy.
To address this, we experimented with increasingly granular sub-tasks. Initially, we started simply by interpreting a contract and using that alongside the call traces to interpret call intent. That showed promise, particularly when using our prompt to extract important events, including key interactions the contract is likely to be used for. However, we found that this approach would lose too much valuable information about a function’s meaning within the contract to be a reliable predictor of intent.
We landed on the best results by unraveling function by function, constructing a temporary function tree, which was helpful to identify the core logic behind a function.
Below you can see the results of this subtask with a little tool we built to quality check the interpretation.
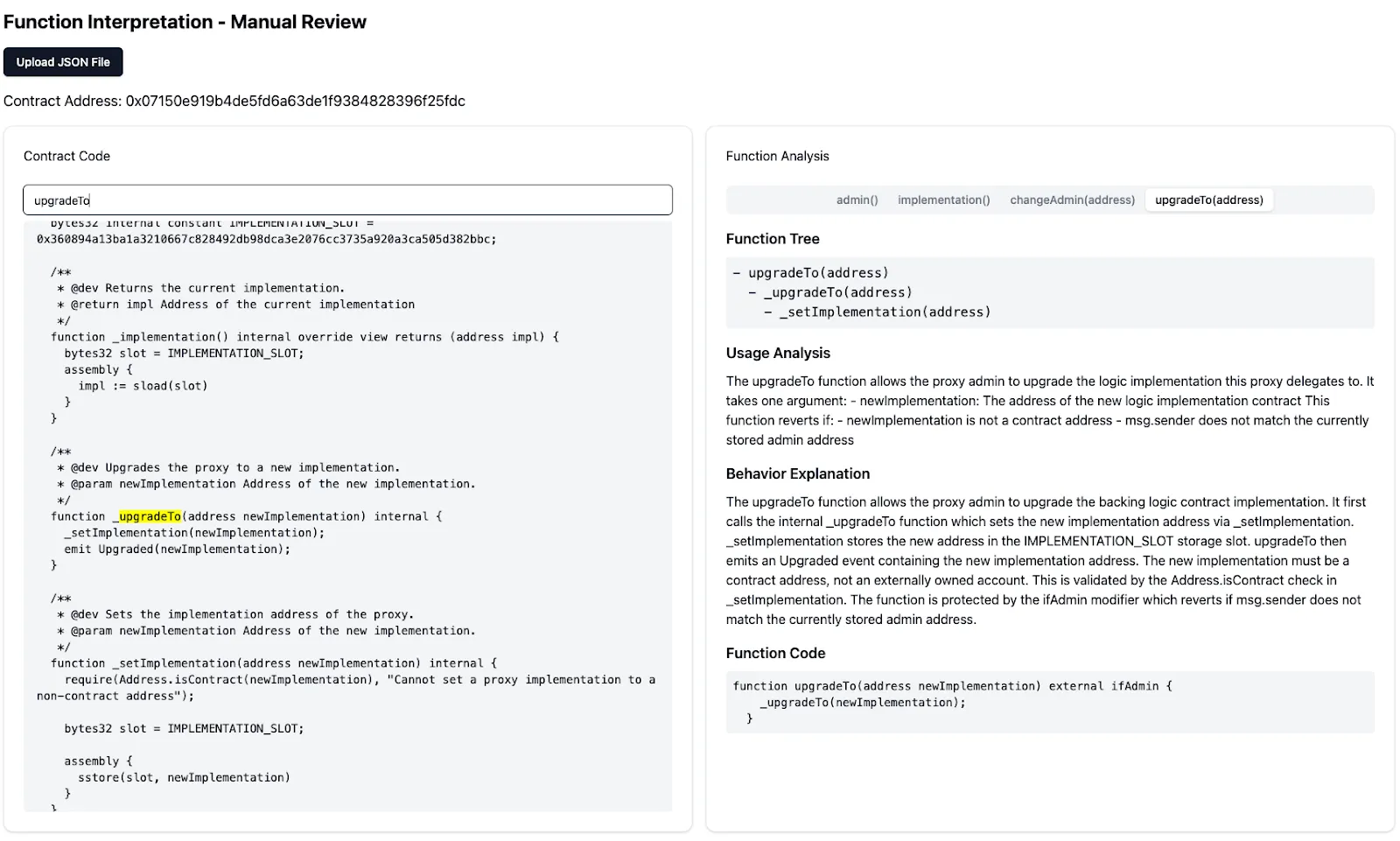
We found a very large number of libraries, services, and techniques to make this process more efficient.
- Both of the popular hosted APIs (Anthropic and OpenAI) have native tooling to help you tweak & test for accuracy without any external libraries. If you are starting, these are definitely worth a try.
- Claude’s Workbench provides a UI-based tool to generate prompts, load your test sample, and compare different versions of prompts against each other. It supports synthetic data generation if you want to increase your sample—while very manual, it is a helpful first tool to start with.
- OpenAI’s native evaluation tool (released in early October) works by comparing completions (generated or saved from real use) against your test set, using some clever presets or custom criteria to measure the property you are controlling quality with.
- Most libraries that abstract the API call to the model with an SDK offer some level of observability and versioning that you can use alongside an evaluation tool later down the line. A lightweight library we experimented with is Ell—Ell Studio versions the traces of every call and stores them locally, so you can take them wherever you want.
- Finally, Weave from Weights & Biases offers a way to log completions and collect feedback in production to continuously curate your test data with edge cases and examples, strengthening your definition of quality and running evaluations against it. A similar tool is available within the langchain ecosystem with Langsmith if you are using that framework.
All the solutions above are a good way of assessing either production data or test data while you are engineering your agentic workflows or pipelines, but in most cases, particularly at the beginning, it will still feel like trial and error. You can’t escape the feeling that some of it is guesswork until you have a large enough sample or mileage in production.
A different take on this is DSPy, as their slogan says: “Programming—not prompting—Language Models.” The approach in DSPy starts the same way: you define the sub-task clearly and define the test set. However, instead of writing the magical combination of words to give the best performance, you look at it as a training job. You choose your modules (say, chain of thought) and optimizers (e.g., introducing a few shots or useful examples of responses to take inspiration from your test set). The library will simulate and measure against your own eval algorithmically (however you define it) until it lands on the optimal one. While we haven’t used this approach for Unravel due to time constraints, this approach felt much more natural in giving confidence in how you approach prompt engineering.
Observations to Evaluate Quality
When it comes to the logic used in your evaluation, there is a very good presentation by Josh Tobin on the subject.
The key learning for us here is that regardless of the methodology, you are ultimately after a way to measure the highest correlation with the outcomes you care about. That means if you use off-the-shelf tests to measure the accuracy of your app or tuned model, you are chasing someone else’s goals. As we saw before, quality IS the product you are crafting with your LLM app, and owning its definition is part of the product design. Owning this end to end, will hedge your solution from degradation of the underlying model (if hosted by others), or set you up for quick evaluation of new ones when they come out.
User testing is important yet expensive, and if in small size can introduce the risk of bias which can ultimately negatively affect your overarching goal. AutoEval is very popular and promising (think of it as an LLM acting as a judge based on a criteria you define).
We used this method with Unravel, as many others, for convenience and scalability during our development. It requires you to have a very good grasp of what correlates with the outcomes you care about, which might not be very clear early on. While in the prototype we didn’t push the boundaries of this aspect, in our retrospective we realized that to do this properly, you probably end up doing a human evaluation first (i.e., a series of experts creating a dataset) and then try to scale it with AutoEval, as it is very hard to come up with finite criteria for most use cases.
There is no one-size-fits-all solution, and as with engineering a pipeline for quality, the process of defining an evaluation pipeline starts with the ground truth of defining quality and what factors correlate with it the most. This can take the form of an instruction to an LLM or a dataset from experts that you can extrapolate and use with AutoEval.
Conclusion
Defining, measuring, and engineering for quality is crucial—especially for production-grade LLM applications.
The three key takeaways for us are:
- The journey to defining quality starts early—before any line of code is written—and relies heavily on defining sub-tasks and curating effective test sets.
- The problem space is still evolving, and the tools available, though promising, are in their early stages.
- Ultimately, don’t be fooled by how simple abstractions make this look. The real work is in defining the goal and designing the evaluation strategy. Iteration and experimentation are key throughout the process, and approaching LLM applications differently, with the mindset of a machine learning engineer, is probably the most important mindset shift to make progress.
If you’d like to demo Unravel, you can check it out at unravel.wtf.